
条件・お題
本記事ではGoogleスプレッドシートを使用します。
テストデータには下記のデータを使用します。
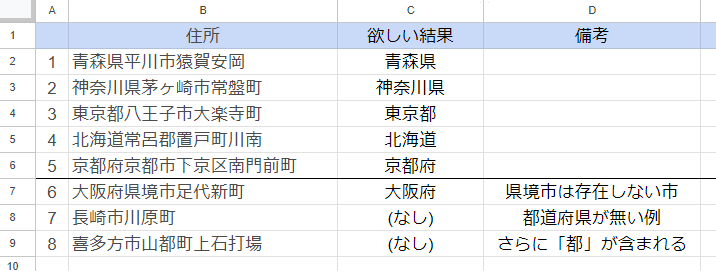
やりたいことは、住所が書かれたセルから都道府県にあたる部分を抜き出して別のセルに表示することです。
6番目以降は存在しない住所を書いてみたり、都道府県を書かなかったりと、意図的に意地悪をしたデータとなっています。
きっかけ
本記事を書こうと思ったきっかけは、下記の投稿が話題になっているのを目にしたからです。
エクセルで「セルA2の住所から県名を抜き出す数式」を考えた人すごい→「これはカッコいい解法ですね」「こういうパズルは楽しい」 – Togetter
ここで使用されている数式はこちら。
=LEFT(A2,3+(MID(A2,4,1)="県"))A2が住所が書かれたセルです。この数式の意味を言葉で書くとこのようになります。
4文字目の文字が「県」の場合は先頭から4文字を、それ以外の場合は先頭から3文字を抽出。
なぜこれで都道府県が抽出できるかというと、都道府県名が下記のパターンのみだからです。
○○県
○○○県
○○都
○○道
○○府
数式の(MID(A2,4,1)=”県”)の部分は論理値のTRUEまたはFALSEとなりますが、3という整数にプラス(+)することで整数への変換が行われるようです(TRUE→1、FALSE→0)。
このテクニックを使うことでこれほどに短く数式を書けることが可能になっています。
これはある意味美しい数式だと思いますが、個人的には「見て何をしているか分かりにくい」数式という印象も受けました。
そこでもっと別の書き方ができないか?と思ったのが本記事を書くきっかけになりました。
REGEXEXTRACT関数
REGEXEXTRACT関数はGoogleスプレッドシートで使用できる関数です。
※Excelについては後述します
REGEXEXTRACT – Googleドキュメントエディタヘルプ
この関数は「正規表現と最初に一致する部分文字列を抽出」する関数です。構文はこちら。
REGEXEXTRACT(テキスト, 正規表現)正規表現とは
正規表現とは、文字列と一致(マッチ)させるためのパターンの文字列です。
英語ではregular expressionと書かれ、regexの短縮名も使用されます。
実際の例で見たほうが分かりやすいでしょう。下記が前述のヘルプページに書かれた例です。
=REGEXEXTRACT("私の一番好きな番号は 241 ですが、友だちの好きな番号は 17 です", "\d+")この数式で正規表現に該当するのは”\d+”です。この文字列が意味するのは「1つ以上の連続した数字」です。
よってこの関数が返す結果は「241」となります。
このように、正規表現では「正規表現専用の記法」を使用します。
なお、正規表現にはいくつかの種類があり、Googleスプレッドシートでは「RE2」という正規表現が使用されるようです。
ここにはサポートされる記法の全てが書かれています。
実践
REGEXEXTRACT関数を使って都道府県を抽出する方法を筆者が考えてみました。
=REGEXEXTRACT(A2,"^.{2,3}?[都道府県]")正規表現の部分である”^.{2,3}?[都道府県]”を分解してみるとこうなります。
| 正規表現 | 意味 |
|---|---|
| ^ | 文字列の先頭 |
| . | 任意の1文字 |
| {2,3}? | 直前の文字の2~3回の連続。最短マッチ。 |
| [都道府県] | どれかの1文字 |
この正規表現を言葉で表すとこのようになります。
文字列の先頭から見て、2文字か3文字(2文字優先)の後に、「都」「道」「府」「県」いずれかの文字というパターン
別の例
探すと、REGEXEXTRACT関数を使う方法で、下記の書き方を紹介するサイトも多くありました。
=REGEXEXTRACT(A2, "..+?[都道府県]")同じように正規表現の部分を分解するとこうなります。
| 正規表現 | 意味 |
|---|---|
| . | 任意の1文字 |
| +? | 直前の文字の1回以上の連続。最短マッチ。 |
| [都道府県] | どれかの1文字 |
つまり、「.」が1文字、「.+?」が1文字以上を表すので「..+?」で2文字以上を表します。
この書き方は前章の方法と比べ、4文字以上ともマッチしてしまいますが、その代わり正規表現は最左マッチという法則があるため文字列の先頭を表す「^」が不要となっています(ちょっと難しいですね💦)。
比較
それぞれの結果を比較してみました。
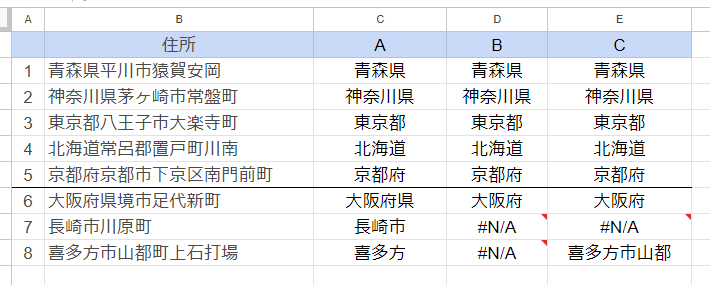
AがLEFT関数とMID関数を使用したケース。Bが筆者が考えたREGEXEXTRACT関数を使ってみたケース。CがREGEXEXTRACT関数の別の例です。
1~5番の「きれいな」住所ではどの方法でも望む結果となりました。
6番の4文字目に「県」の文字が現れる住所ではAの方法では正しくない結果となりました。ただしこのようなエラーになる住所はどうやら現在の日本には存在しないようです(確信は持てませんが)。
8番の住所ではCの方法では途中の「都」の文字にマッチしてしまいました。
ちょっと都合が良く用意されたデータのような気もしますが、この中では筆者の考えた方法が一番間違った結果にはなりませんでした。
最強の方法
ここまで色々と書いてきましたが、例えば「埼玉県」を「埼王県」と書き間違えた住所が存在する場合、これまでの方法ではそれも抽出してしまいます。
そこで、最も間違いないある意味最強の方法はこの書き方になります。
=REGEXEXTRACT(A2,"北海道|青森県|岩手県|宮城県|秋田県|山形県|福島県|茨城県|栃木県|群馬県|埼玉県|千葉県|東京都|神奈川県|新潟県|富山県|石川県|福井県|山梨県|長野県|岐阜県|静岡県|愛知県|三重県|滋賀県|京都府|大阪府|兵庫県|奈良県|和歌山県|鳥取県|島根県|岡山県|広島県|山口県|徳島県|香川県|愛媛県|高知県|福岡県|佐賀県|長崎県|熊本県|大分県|宮崎県|鹿児島県|沖縄県")正規表現では「|」で区切られた文字列のどれかとマッチします。
もう一段階進めると、47都道府県をセルに書いたマスタを別シートに用意し、そのセル範囲にPREFSなどの名前を付ければ、下記のように書き換えることができます。
=REGEXEXTRACT(A2,TEXTJOIN("|",TRUE,PREFS))結論
結局の所、どの方法が100%正しいというものは無いです。
住所情報が正しいことが保証されていたり都道府県を抽出するのが一回切りの作業であれば、正しい結果を得ることができればそれが正しい方法と言ってもいいでしょう。
一方で住所情報に間違いが含まれている可能性があったり、それが大量の住所情報で目視確認がやりにくかったり、将来に渡ってずっと使い続けるブックにしたい場合は、より正確性を重視した方法を取るのが良いでしょう。
ExcelでREGEXEXTRACT関数は使える?
ここまでGoogleスプレッドシートでの話をしてきましたが、Excelではどうなのでしょう?
このようなMicrosoftの記事がありました。
New Regular expression (Regex) functions in Excel
(投稿日:2024年5月21日)
ここにはREGEXEXTRACT、REGEXTEST、REGEXREPLACEという3つの関数がExcelで使える(ようになる)と書かれています。
この記事が書かれた時点ではこれらの関数はプレビュー関数(ベータ版みたいなもの)であり、広くリリースされるまでには仕様が変わるかも知れないと書かれています。そのため、大事な用途のブックで使うことはおすすめしないとも書かれています。
この関数ヘルプページを見ると、GoogleスプレッドシートのREGEXEXTRACT関数と同じような使い方ができそうな雰囲気です。
関数が正式にリリースされたらExcelでもどんどん正規表現を使ってみましょう!


コメント